WHAT IS CACHING…?
Caching is a system to improve performance by temporarily copying frequently accessed data to fast storage located close to the application. Storage must be located closer to the application than the original source to significantly improve response times for client applications by serving data more quickly.
CACHING IN DISTRIBUTED APPLICATIONS
Distributed applications typically implement either or both of the following strategies when caching data:
- Using a private cache, where data is held locally on the computer running an instance of an application or service. If you have multiple instances of an application that uses this model running concurrently, each application instance will have its own independent cache holding its own copy of data. But the downside is -> it is likely that different application instances will hold different versions of the data in their caches.
- Using a shared cache, serving as a common source which can be accessed by multiple processes and/or machines. Using a shared cache removes the concern of data being differed in each cache, which happens in case of in-memory caching. Different application instances see the same view of cached data by locating the cache in a separate location, typically hosted as part of a separate service
ADVANTAGES & DISADVANTAGES OF SHARED CACHING
Advantage is “Scalability” - Many shared cache services are implemented by using a cluster of servers, and utilize software that distributes the data across the cluster in a transparent manner. An application instance simply sends a request to the cache service, and the underlying infrastructure does the part of finding out at which data location the data resides in the cluster. You can easily scale the cache by adding more servers.
Disadvantage is – It is slower than the in-memory / in-role cache and at times implementing a separate cache may add complexity to the solution.
WHEN DATA SHOULD BE CACHED..? / WHEN CACHING SHOULD BE USED …?
The more data that you have and the larger the numbers of users that need to access this data, the greater the benefits of caching become. A database may support a limited number of concurrent connections, but retrieving data from a shared cache instead will allow the application to get the data even if the concurrent no. of connections are exhausted. Additionally, if the database is down, client applications can continue working by using the data held in the cache.
Also you should not use the cache as the authoritative store of critical information. Ensure that changes that your application cannot afford to lose, are always saved to a persistent data store. In this way, if the cache is unavailable, your application can still continue to operate by using the data store in the persistent data store.
But, you should consider caching data that is read frequently but that is modified infrequently.
SEEDING AS A CACHE POPULATING STRATEGY - A cache may be partially or fully populated with data in advance, typically when the application starts (an approach known as seeding). However, it may not be advisable to implement seeding for a large cache as this approach can impose a sudden, high load on the original data store when the application starts running.
GENERAL POINTS WHICH CAN BE TAKEN INTO CONSIDERATION WHILE DECIDING CACHING –
- Some or all of this data can be loaded into the cache at application startup to minimize demand on resources and to improve performance.
- It may also be appropriate to have a background process that periodically updates reference data in the cache to ensure it is up to date, or refreshes the cache when reference data changes.
- Data expiration rules can be set for the entire cache as a whole or on an individual objects. The timer needs to be set cautiously so that neither stale data copy is maintained by setting it too long, nor objects start getting expired quickly by setting the expiration time too short. The object-specific expiration policies override the cache based expiration policy, if configured any.
- A cache should not be the primary repository of data; this is the role of the original data store from which the cache is populated. The original data store is responsible for ensuring the persistence of the data.
- There is a facility to set the eviction rule, wherein usually the Least Recently Used (LRU) data from cache is removed first when the cache available memory starts becoming scarce. This can be set to other options wherein the FIFO method of data clearance can be opted. But this doesn’t guarantee the preservation of required data.
- For the above reason, choosing the cache memory size (which starts from 53 GB in case of Redis) needs to be choose carefully so that if the underlying application is manipulating data in large volume then the memory should not become scarce.
APPROACHES FOR UPDATING THE CACHE DATA BY THE APPLICATION –
There are following 2 approaches –
- Optimistic – where before updating the cache data, the application ensures that the same data exists in cache which has was retrieved by the application from cache, last time the application accessed it. It is just to make sure that the cache data can be overwritten with the new data, so that all applications consuming the same shared cache starts getting the updated / modified / new data.
- Pessimistic – Here the application locks the cache data so that other applications will not be able to update it. This removes the risk of same cache data getting updated by multiple instances of same applications at the same time (data update collision) The downside of this approach is when such locking happens, it affects the scalability by allowing multiple instances of the same application to access the shared cache
USING PRIVATE CACHE ALONG SIDE THE SHARED CACHE –
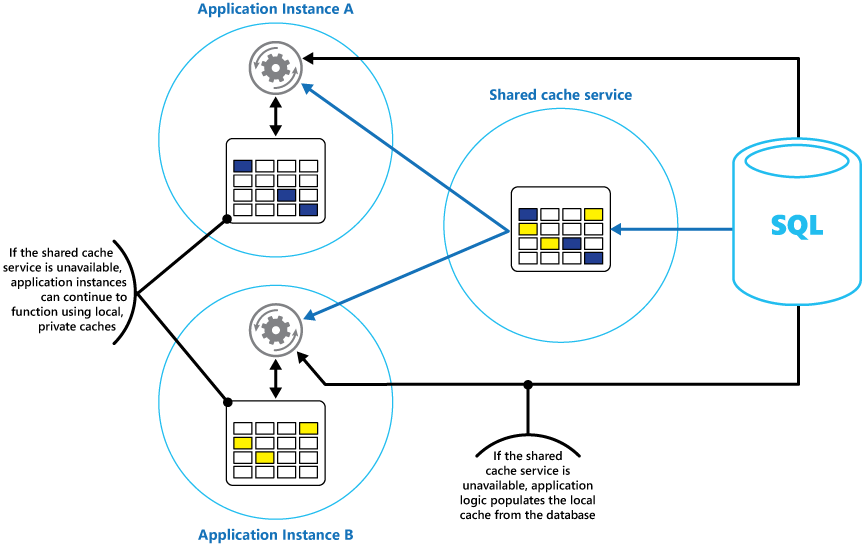
As shown in the following image, if the shared cache is down, instead of the application coming to a halt, it can access the data from database, store in local cache i.e. In-Role caches and resume application’s functioning till the shared cache is up and running.
WHAT IS CACHE IS AZURE…?
Microsoft Azure Cache is a family of distributed, in-memory, scalable solutions that enable you to build highly scalable and responsive applications by providing super-fast access to your data.
Microsoft Azure Cache is available in the following offerings.
- Azure Redis Cache
- Managed Cache Service
- In-Role Cache
WHAT IS AZURE MANAGED CACHE…?
This is a shared cache, serving as a common source which can be accessed by multiple processes and/or machines.
WHAT IS AZURE IN-ROLE CACHE …?
This is a private cache mechanism, where data is held locally on the computer running an instance of an application or service. In-role cache is assigning memory from worker role or web role for caching. This is of 2 types / there are 2 topologies as under –
- Dedicated – where a separate worker role is dedicated for caching and all its memory is utilized for caching
- Co-located – where some % of web role’s memory (say 20%) is kept aside for caching. So if there are 2 web roles, so there will be 2 caching memories.
In-Role cache is hosted by instances of a web or worker role, and can only be accessed by roles operating as part of the same cloud service deployment unit (a deployment unit is the set of role instances deployed as a cloud service to a specific region).
WHAT IS AZURE REDIS CACHE..?
Microsoft Azure Redis Cache is based on the popular open source Redis Cache. It gives you access to a secure, dedicated Redis cache, managed by Microsoft. A cache created using Azure Redis Cache is accessible from any application within Microsoft Azure. Azure Redis runs as a service spread across one or more dedicated machines.
Redis is a key-value store, where values can contain simple types or complex data structures such as hashes, lists, and sets. Keys can be permanent or tagged with a “limited time to live”, at which point the key and its corresponding value are automatically removed from the cache.
IMP. Note by Microsoft - Azure also provides the Managed Cache Service, which is based on the Microsoft AppFabric Cache engine. This enables you to create a distributed cache that can be shared by loosely-coupled applications. The cache is hosted on high-performance servers running in an Azure datacenter. However, this option is no longer recommended and is only provided to support existing applications that have been built to use it. For all new development, use the Azure Redis Cache instead.
Another note - Azure Redis Cache does not currently support clustering. If you wish to create a Redis cluster you can build your own custom Redis server.
AND WHAT IS POPULAR OPEN SOURCE REDIS CACHE..?
Redis is not a plain key-value store, actually it is a data structures server, supporting different kind of values. What this means is that, while in traditional key-value stores you associated string keys to string values, in Redis the value is not limited to a simple string, but can also hold more complex data structures like –
- Binary safe strings
- Sorted / unsorted lists of strings
- Bit arrays etc.
For more information read on - http://redis.io/topics/data-types-intro
BEST PRACTICE – REDIS SECURITY – Consider following points –
- Redis is designed to run inside a trusted environment and be accessed only by trusted clients. Redis supports password authentication model i.e. providing access to those clients which have authenticated themselves as valid entities (it is possible to remove authentication completely, although this is not recommended). For login security, you must implement your own security layer in front of the Redis server and all client requests should pass through this additional layer.
- Redis does not directly support any form of data encryption, so all encoding must be performed by client applications.
- Redis does not provide any form of transport security, so if you need to protect data over network, you should implement an SSL proxy.
AZURE REDIS PLANS AVAILABLE –
Azure Redis Cache is available in the following two tiers.
- Basic - single node, multiple sizes from 250 MB up to 53 GB.
- Standard - two node Primary/Replica, multiple sizes from 250 MB up to 53 GB. The standard tier offering has a 99.9% SLA.
DIFFERENCE BETWEEN AZURE REDIS CACHE AND (AZURE MANAGED CACHE SERVICE & IN-ROLE CACHE)
The in-role cache is distributed across multiple virtual machines, while each Azure Redis Cache instance is hosted on a single virtual machine, with a replicated cache on a second virtual machine in the standard offering.
WHAT ARE THE ADVANTAGES AND DISADVANTAGES OF EACH CACHE COMPONENT…?
Redis Cache –
- Being the open source, it has vibrant ecosystem built around it. It is just not a “key-value pair” type cache mechanism, but also allow perform operations like to sorting lists stored in cache; getting the member in the highest ranking in the sorted list; support for transaction operations on data stored in cache.
- Provides 99.99% SLA
- It’s a distributed cache system
- Provides high availability by providing a primary and backup cache; where backup cache is made available, when there is a failure with the primary cache.
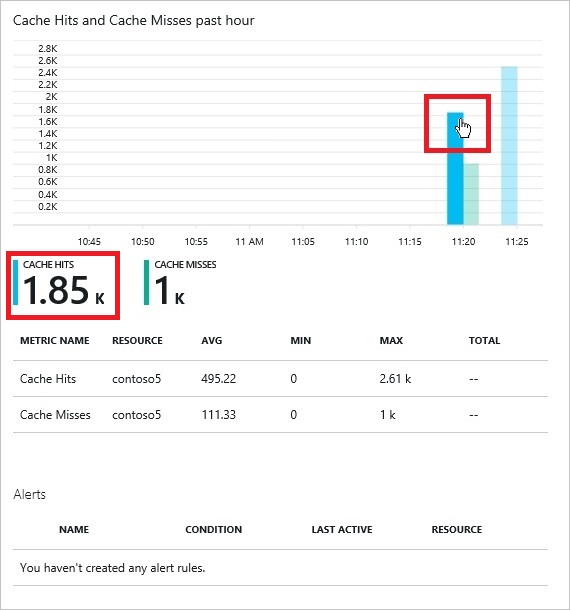
- Diagnostic feature is available, where one can see - Cache Hits, Cache Misses, Get/Set Commands, Total Operations, Evicted Keys, Expired Keys, Used Memory, Used Bandwidth and Used CPU. This is available along with visualization on Azure portal.
- Eviction policies are available – policies for freeing cache memories.
- Alerts rule to notify the cache administrator can be configured when the cache is seeing evictions. This in turn might signal that the cache is running hot and needs to be scaled up with more memory.
- ASP.Net Page output cache support – Yes
- ASP.Net Page output cache support - Yes
Managed Cache Service –
- Provides 99.99% SLA
- It’s a distributed cache system
- Provides high availability by providing a primary and backup cache; where backup cache is made available, when there is a failure with the primary cache.
- Expiration facility is available in following modes –
- Absolute – A Cache items gets expired after 10 minutes (which is a default expiration time, which can be configured) from the timestamp when the item was placed in the cache.
- Sliding – an item gets expired after 10 minutes from the last-accessed time stamp.
- Never – An item will never expire once placed in cache.
- ASP.Net Page output cache support - Yes
- Eviction policies are available – policies for freeing cache memories
- ASP.Net Session storing support - Yes
In-Role cache –
- Doesn’t provide any SLA
- It’s NOT a distributed cache system. It’s a self hosting cache system.
- No High availability feature is available as there is no backup cache
- ASP.Net Page output cache support – NO
BENCHMARKS FOR CHOOSING BETWEEN BASIC AND STANDARD PLANS –
- If you desire an SLA for your cache, choose a standard cache which has a 99.9% SLA.
- If your cache has a high throughput, choose the 1 GB size or larger, so that the cache is running using dedicated cores.
- Redis is single-threaded, so having more than 2 cores does not provide and additional benefit. VM size should be larger, instead.
HOW TO CREATE A CACHE – Refer to https://azure.microsoft.com/en-in/documentation/articles/cache-dotnet-how-to-use-azure-redis-cache/
CACHE DIAGNOSTICS DATA – is the data about hits and Gets And Sets are stored in a Azure Storage account. You can set till how many days this data needs to be retained. For best performance the storage account should be in the same region where the Redis cache is hosted. To view the stored metrics, examine the tables in your storage account with names that start with WADMetrics
FOLLOWING DATA METRICS IS STORED AS DATA –
- Cache hits – Successful key lookups
- Cache Misses - Failed key lookups
- Connected clients - The number of client connections to the cache during the specified reporting interval.
- Expired keys - The number of items expired from the cache
- Gets - The number of get operations from the cache during the specified reporting interval.
- Redis Server Load - The percentage of cycles in which the Redis server is busy processing and not waiting idle for messages. If this counter reaches 100 it means the Redis server has hit a performance ceiling and the CPU can't process work any faster.
- Sets - The number of set operations to the cache
- Used memory - cache memory used in MB
- CPU - % CPU utilization of the Azure Redis Cache server
CHART FOR SEEING DIAGNOSTIC MATRIX -

MAXMEMORY EVICTION POLICIES – are the policies which decide how the data needs to be removed from cache when the ceiling limit is reached. Available eviction policy names are available in drop down. Redis server’s reaction is depending which policy has been selected.
Following policies are available – Read on - http://redis.io/topics/lru-cache#eviction-policies
To pick the right eviction policy is important depending on the access pattern of your application. You can reconfigure the policy while the application is running, and monitor the number of cache misses and hits.
MAXMEMORY RESERVED - The maxmemory-reserved setting configures the amount of memory in MB that is reserved for non-cache operations such as replication during failover. This setting is available only with the Standard cache plans.
WHAT WE GET IN A DEFAULT REDIS SERVER CONFIGURATION – Read the “Default Redis server configuration” section at https://azure.microsoft.com/en-us/documentation/articles/cache-configure/
REDIS CONSOLE – Redis console is used for firing Redis commands which are common for open source source Redis as well as for azure Redis. But this is available only for Standard Cache Plans.


Not all commands from open source Redis is supported over Redis cache, as it is managed through Azure portal.
No comments:
Post a Comment